
The notion of an “AI software engineer” is swiftly shifting from conceptual to tangible, transforming the landscape of software development as we know it.
Technology’s progressive march has consistently eased the paths for software engineers:
- Devin debuted as the world’s inaugural AI software engineer last year, marking this paradigm shift.
- Cursor is emerging as a worthy alternative to traditional VS Code, integrating AI seamlessly into development environments.
- Consider GPT-4 and Claude, which offer assistance in coding and bug fixes with remarkable dexterity.
These advancements indicate a trajectory where software engineering becomes increasingly intuitive, empowered by continued human inquiry into LLM reasoning.
AI Software Engineers vs. Traditional LLMs
How does an AI software engineer stand apart from a simpler LLM? Certainly, LLMs possess code-writing prowess. Yet, there’s more depth here worthy of exploration:
An AI software engineer doesn’t merely write code—it navigates an entire repository, discerning which files to alter based on a given task.
Imagine an AI project bogged down by a loading issue when selecting the Mistral model:
A software engineer must pinpoint the errant file and apply the fix. It might start with inspecting where the model loader resides, and if deeper issues are rooted elsewhere, diving into those dependencies.
This level of holistic inspection is beyond a regular LLM, which requires explicit direction towards the problem-containing file before attempting repairs.
An AI software engineer, like its human counterpart, iteratively crafts PRs (pull requests) to resolve distinct facets of the codebase.
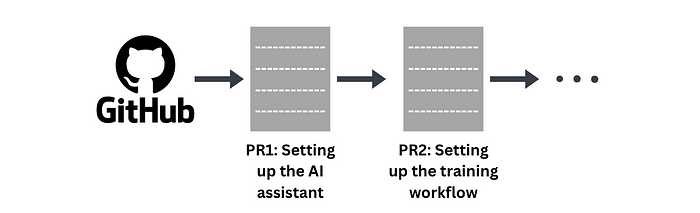
Coding these enhancements could either be a self-driven process or guided through user prompts.
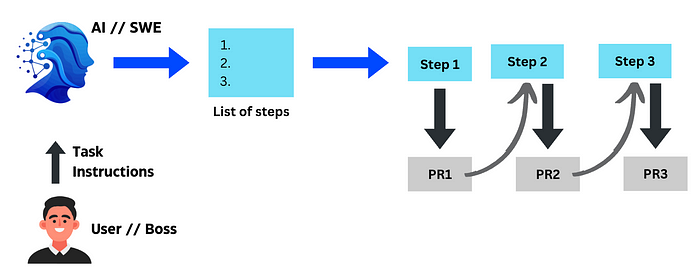
Forging an AI Software Engineer (SWE)
Considering recent advancements like the DeepSeek model, you might ponder if LLMs equipped with Reinforcement Learning (RL) can transcend into adept software engineers. I’d encourage checking my earlier blog illustrating RL’s versatile training scope.
Discover Untapped Research Opportunities with DeepSeek-R1
With RL’s ability to self-solve without explicit instruction, we must ask:
Could RL equally enhance our software engineering tasks?
Defining the Task
Our mission is crafting an AI capable of automatically applying necessary adjustments to a repo—exactly as a skilled engineer might.
The Journey to Train an AI SWE
To train an AI like DeepSeek, an identical RL pipeline refinements are applied:
This universally adaptable technique, initially honing reasoning, suggests amplified efficiency across varied domains, including our SWE ambitions.
Does focusing on explicit coding scenarios kindling even better outcomes?
Data Assembly
Data collection ascends as the first step, aimed at illuminating the LLM with instructions on revising:
- Current code configurations
- Functions needing transformation
Where does such data dwell?
Git PRs provide a trove of insights:
A Git PR orchestrates merging proposed branch changes. A developer actions amendments, documents them via commit messages, before merging with the main repository, capturing the evolution chronicle prior to AI interaction.
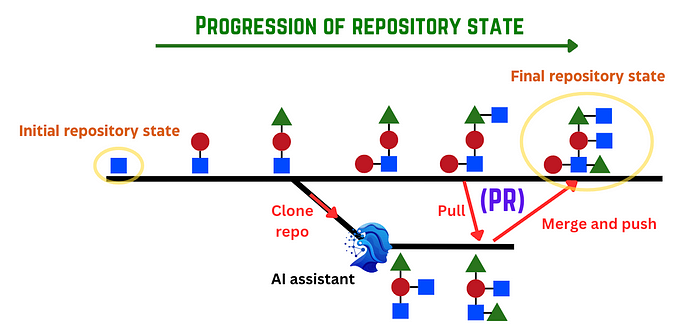
Through harvesting numerous public repository PRs, the foundation is laid for teaching the LLM code innovation considering the task and prior state.
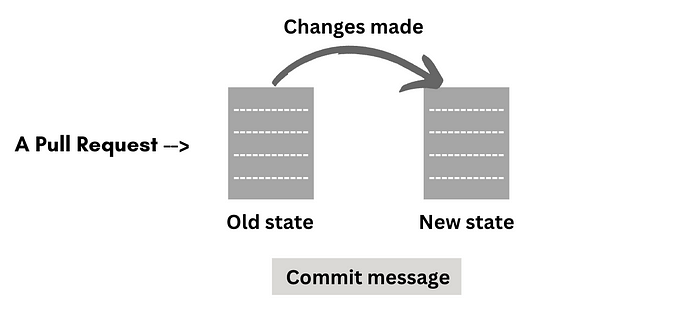
Ingenious Prompting
Confronting dataset complexities, a strategic approach to LLM prompting during training arises:
Offering snippets—changed files pre/post commit and relevant
Even unchanged files, interconnected by the ecosystem’s stability, provide valuable contextual learning.
Calculating the Reward
In shaping incentives, we simplify: contrast the LLM’s output with the expected PR file state. Closer resemblance equates to richer rewards.
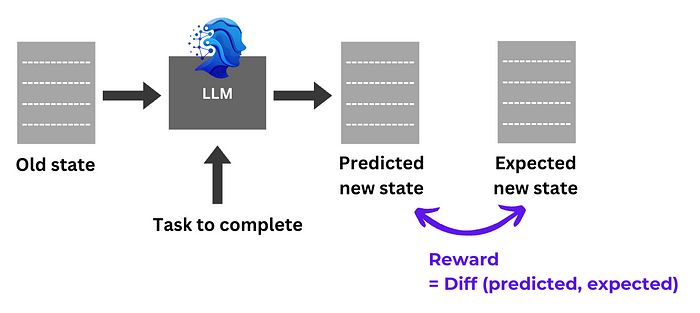
Training Initiatives
The core process unfolds as data input, garnering LLM outputs, subsequent evaluation, and rewards directed at refining output-warranting policies for consistent alignment.
Amplifying Efficiency
Curriculum Learning
Layering difficulty within RL’s learning loop enriches effectiveness mirroring progressive academic enlightenment:
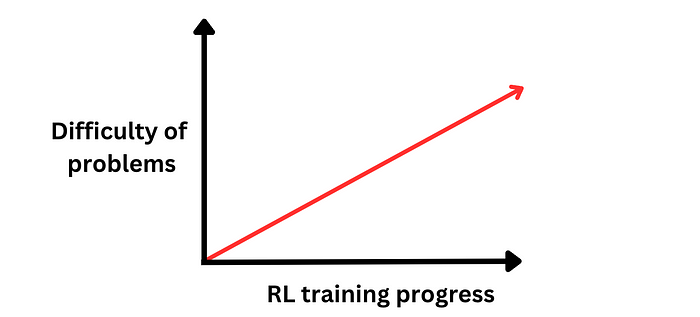
Ordering PRs—from minimalist changes to complex calamities—might foster nuanced reasoning advancements.
Refining Data and Rewards
Cleaner data and smarter rewards underpin potential leaps in LLM proficiency:
- Data Quality: Ensuring PRs mirror ideal engineering habits demands curated, quality datasets—challenging in the vastness of online repositories.
- Reward Precision: Deviation between LLM and repository might breed negative reinforcement, even when LLM’s solution excels, warping guidance.
Undoubtedly, refining data and incentives emerges as rich grounds for future discourse and innovation.
Conclusion
The vision of an AI software engineer is not distant but nearly in our grasp, with open-source accessibility beckoning worldwide developers.
Exploring the layers of AI engineer crafting unveils myriad efficiencies yet to be unearthed. As the field burgeons, seeding research in RL-augmented LLMs promises untold advancements. Embrace this emerging domain; it’s an opportune moment to delve in, as I am this year.




{kind=link}